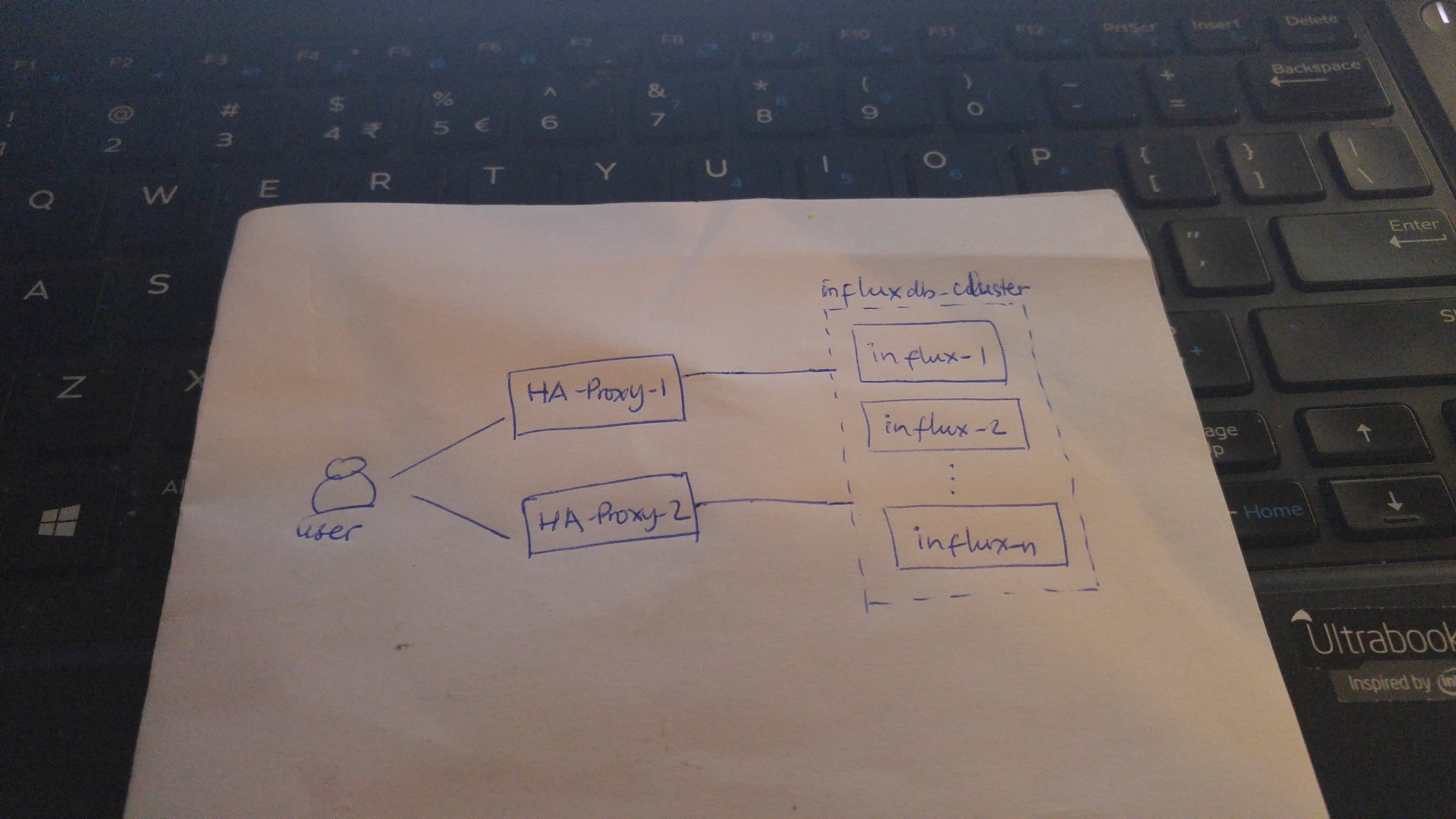
In any good IT platform, main features must be prepared in front, by-design. Scalability and high availability are two must-have capabilities in any big data system today. Out-of-service, inaccessible, server busy, and too long response time are some issues that are avoided by any organization for years.

Impressed by the performance of Influxdb compared to others, I tried to prove the scalability and high availability of an Influxdb cluster as IoT storage. In this proof-of-concept, I used docker containers to simulate the real-world servers. In my previous post, I covered how good compression ratio InfluxDB has.
Check out my GitHub to see the process: https://github.com/agungw132/influxdb-cluster.
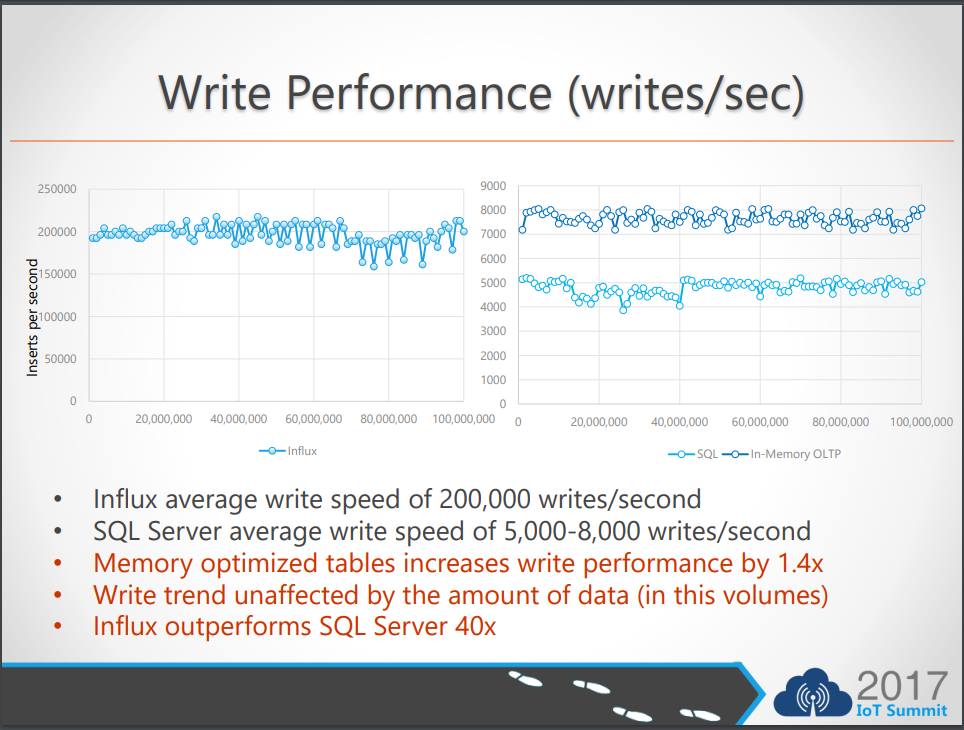
*Slide captured from: