Next: How to install a standalone Hadoop
Part 1: Understanding Apache Hadoop as a Big Data Distributed Processing & Storage Cluster
In the last post, I discussed on which occasion we prefer distributed approach such as Hadoop and Spark over the monolithic approach. I will discuss more detail about Apache Hadoop in this article. This article is divided into two parts, i.e., part 1 will cover stand-alone mode installation of Hadoop, and part 2 will cover installation Hadoop in a cluster.
According to Wikipedia, Hadoop which was originally developed by Doug Cutting and Mike Cafarella in 2006, spawned the idea from Google File System and “MapReduce: Simplified Data Processing on Large Clusters” paper that was published in October 2003. What an exhilarating story is that Doug named the application after his son’s toy elephant. It is an active project, started from version 1.0 until currently already reaches version 3.1. It also has a large ecosystem, growing from only distributed data processing and storage system to a comprehensive system, including data ingestion, data governance, data analytics, and data security.
Hadoop 1.X
The architecture of Hadoop 1.X storage cluster, coined as Hadoop Data FileSystem (HDFS), consists of :
1) single namenode, as the controller/manager of the Hadoop cluster. It keeps metadata of the file system, i.e., information about the directory tree of all files stored in the cluster. It also tracks where across the cluster the file data resides. When clients want to do a file operation (add/copy/move/delete) to Hadoop cluster, they interact with NameNode. The NameNode responds to the request by returning a list of relevant DataNode servers where the data lives.
2) multiple datanodes that stores the data in the Hadoop cluster. A huge size data is chopped into many chunks, namely blocks. Multiple copies of each block will be stored in multiple datanodes. Such as data replication is supposed to ensure fault-tolerance.

DataFlair explained very well how Hadoop 1.X works in the following figure. On startup, a datanode connects to the namenode. It keeps on looking for the request from namenode to access data. Once the namenode provides the location of the data, client applications can talk directly to a datanode, while replicating the data, datanode instances can talk to each other.

Once the data resides in datanodes, how could we process the data such as aggregating the data? MapReduce framework is then used. The framework introduced data processing management (i.e., how data processing is decomposed into multiple mapping & reducing steps) and resource management (i.e, how each mapping & reducing process acquires resources). We will cover the data processing management later in another article.
Resource management involves two new components, i.e.,
1) Jobtracker as the processing manager which is responsible to ensure a job sent by clients is executed completely in the cluster. Jobtracker process usually runs on the machine where a namenode resides. Once it receives the requests for MapReduce execution from the client, jobtracker talks to the namenode to determine the location of the data. Jobtracker finds the best tasktracker nodes (which resides on datanodes) to execute tasks based on the data locality (proximity of the data) and the available slots to execute a task on a given node. Jobtracker monitors the individual tasktrackers and the submits back the overall status of the job back to the client. When the JobTracker is down, the file system will still be functional but the MapReduce execution cannot be started and the existing MapReduce jobs will be halted.
2) Tasktracker as the datanode’s partner and workers of job tracker. tasktracker will be in constant communication with the jobtracker signalling the progress of the task in execution. Mapper and Reducer tasks are executed on datanodes administered by tasktrackers. Tasktrackers will be assigned mapper and reducer tasks to execute by jobtracker. Tasktracker failure is not considered fatal. When a tasktracker becomes unresponsive, jobtracker will assign the task executed by the tasktracker to another node.

Hadoop 2.X
Hadoop 2.X later came to improve Hadoop 1.X. The major improvement of Hadoop 2.X over 1.X is decoupling of resource manager (i.e., jobtracker & tasktracker) from MapReduce framework into a separate entity, namely Yet Another Resource Negotiator (YARN). By doing so, resources could be attached to any data processing framework outside MapReduce. Monitoring, development, operation, and maintenance of the resource manager also now become independent. However, the architecture now becomes more complex and increased latency is inevitable.
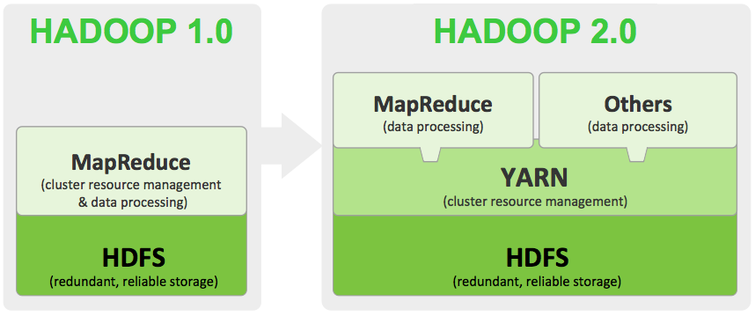
YARN introduced two new entities, i.e.,
1) Resource Manager which takes over jobtracker in Hadoop 1.X.
2) Node Manager which takes over tasktracker.

Other changes in Hadoop 2.X are as follows.
1) Hadoop Federation: separating the namespace layer (info about block or folder, info about directory and files, responsible for file-level operation- create/modify/delete, directory or file listing) with block storage layer (block Management [block information, replication, replication placement] and Physical Storage [stores the blocks, provide read & write access])
2) namenode high availability: introducing standby namenode, namely secondary namenode, which is an exact replica from the primary namenode. Both primary and secondary namenode will be in sync all the time with auto failover mode, i.e., if the primary is down, passive secondary namenode is always there to take over the operation. Consequently, Hadoop achieves high availability and fault-tolerance by eliminating single point failover.
3) native windows support
4) datanode caching for faster access
5) HDFS snapshots: snapshots can be now created for protection for user errors, reliable backups, and used for disaster recovery.
Hadoop 3.X
Currently, Hadoop is at 3.X version. What differs Hadoop 3.X from 2.X? There are a number of improved things, i.e.,
1) Java version: Hadoop 3.X leverages Java 8 instead of Java 7 used by 2.X
2) Fault tolerance mechanism: Hadoop 2.X uses replication of data blocks for fault tolerance, whereas 3.X uses erasure coding. 3x replication factor in 2.X results in 200% overhead storage. Meanwhile, erasure coding in 3.X reduces the overhead to only 50%.
3) YARN timeline service: There is scalability issue of YARN timeline service in Hadoop 2.X which is now resolved in Hadoop 3.X.
4) Standby namenode: Hadoop 2.X only supports one standby namenode compared to multiple standby namenodes in 3.X.
5) Heap management: In Hadoop 2.X, heap size is static and manually configured via HADOOP_HEAPSIZE. Meanwhile, Hadoop 3.X provides dynamic heap size, i.e., auto-tuning of heap.
Next: How to install a standalone Hadoop