Contents
High performance computing (HPC): What is it and what is it used for?
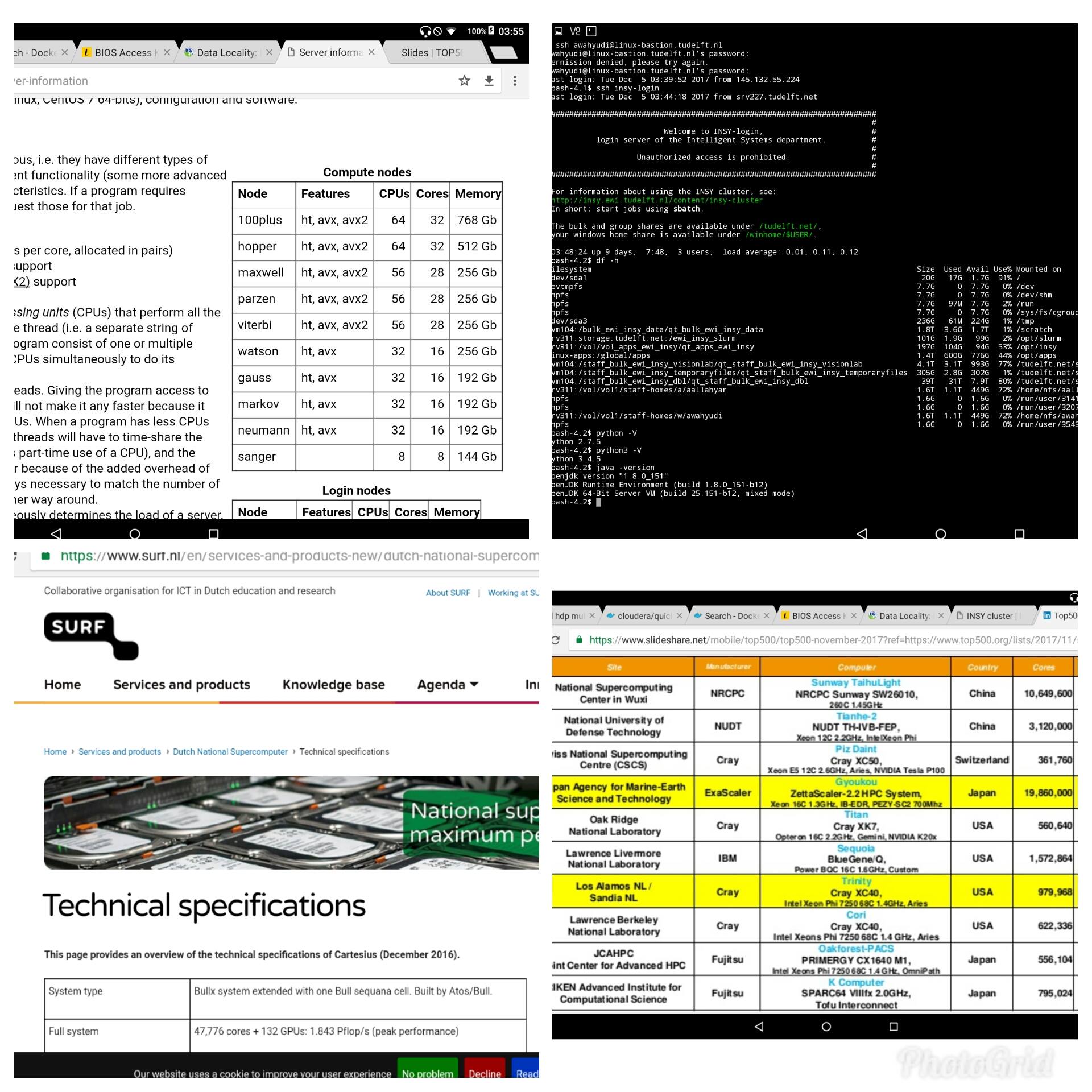
I am so grateful to have access to wealthy resources of TU Delft, the Insy HPC cluster. It has ~ 12K cores for research computation. However, it is very small compared to Cartesius, the Dutch National Supercomputing, which has ~48K cores or Sunway Taihulight, the world’s biggest HPC (as of Dec 2017) which has 10,600K cores.
HPC is needed to solve complex computation problems such as finding new oil reserves, DNA analysis, logistics optimization, drug discovery, etc. As many countries race to be the leader in innovation, the availability of HPC in their research environment is a must.
Typical HPC architecture
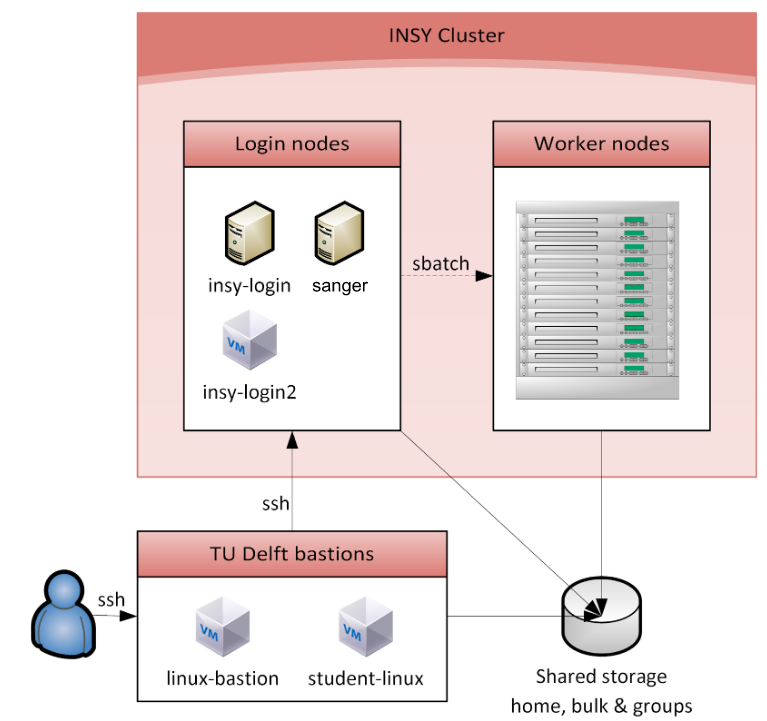
HPC usually has three main components, i.e., 1) worker nodes that serve as resources pool; 2) login nodes as the front gate for any access and the workload manager for any jobs; and 3) storage pool that could be Network File System (NFS), Samba, and other network storage mechanism. In most cases, an additional single gateway is installed to allow the HPC cluster to be securely accessed from the Internet (outside). Such an architecture requires us to forward any used ports (e.g., 8080 for web) from INSY cluster to gateway nodes (e.g., TU Delft bastions) if we need those ports.
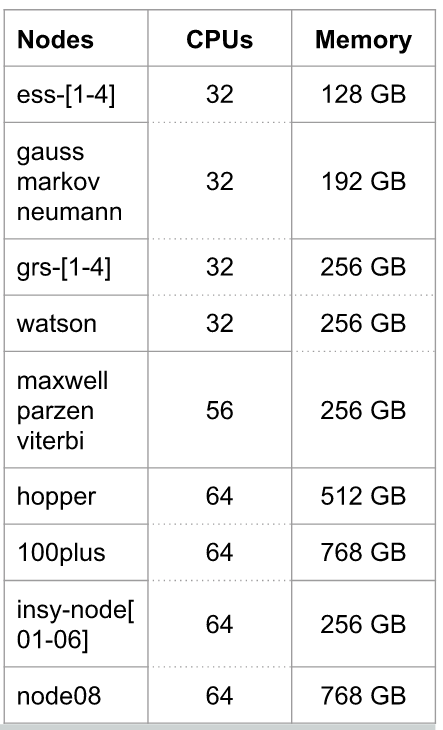
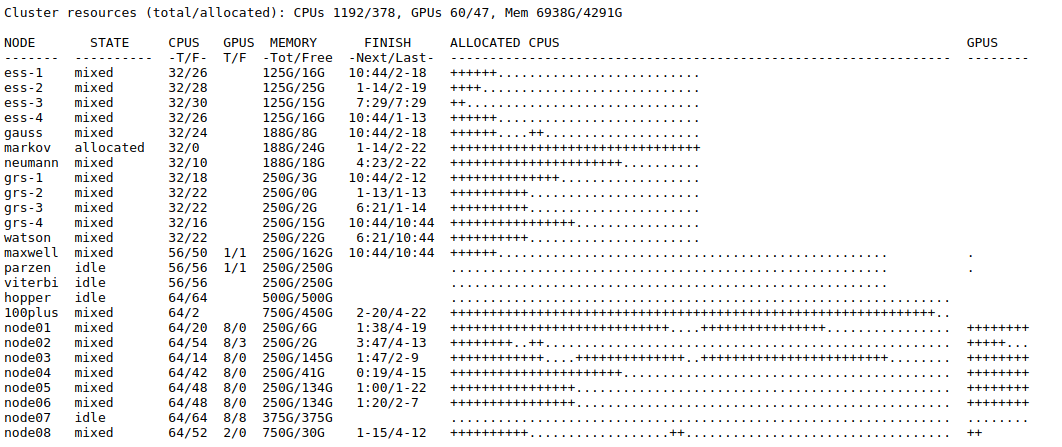
Worker nodes of INSY cluster consist of multiple machines with different resources (CPUs, GPUs, RAMs). In total, INSY cluster has almost 12K cores. However, cores that can be used by each user for every job are limited and ruled by the system administrator. It differs from an organization to another.

How to use it
Simple Linux Utility for Resource Management (SLURM) is usually used to manage the jobs and workload of the HPC, i.e., in terms of usage policy such as priority, allowable resources, allowable execution time, and quality of service (QoS). It also manages successfulness of job execution by having retrying and rescheduling mechanism.
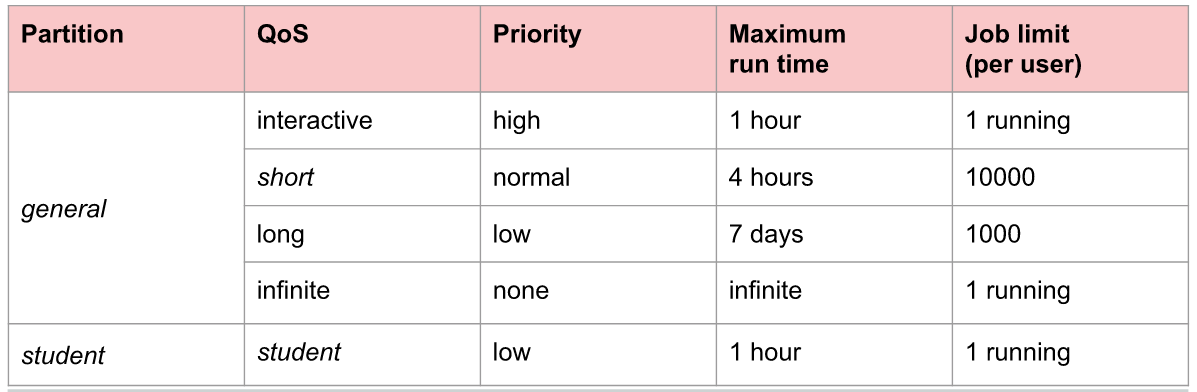
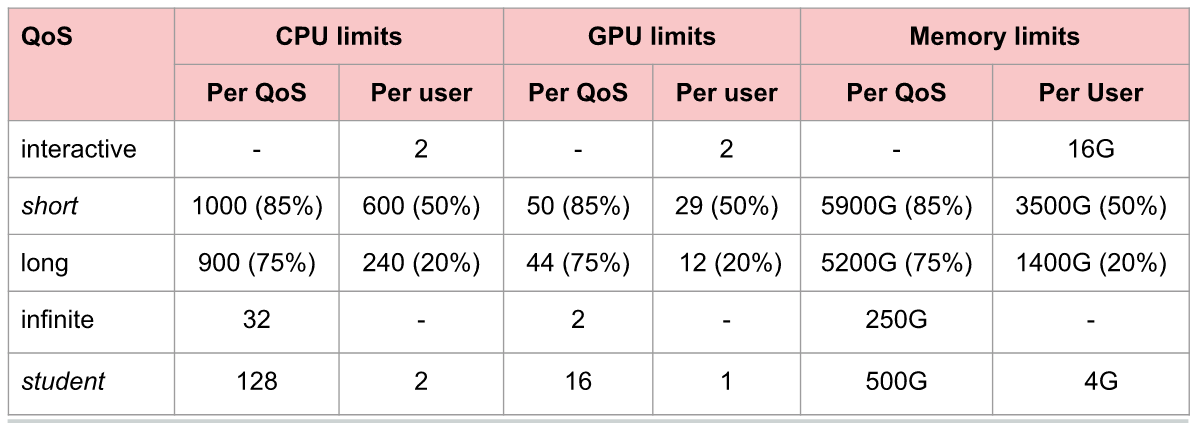
Every request sent to SLURM should include the following properties:
--partition : see usage policy --qos : see usage policy --time : max. elapsed time (should be less than the number in usage policy) --ntask : number of parallel tasks --cpus-per-task : number of CPUs per task (should be less than the number in usage policy) --gres : type and number of GPUs (e.g., gpu:pascal:1) --mem : amount of RAMs (should be less than the number in usage policy) --mail-type : forward the notification/report to email --workdir : absolute path of working directory --output : absolute file path of the output of console --nodelist : list of node
Every HPC usually has shared installed applications that are common among users, such as Matlab, CUDA, CuDNN, etc. Thus, every user needs not to install the applications which greatly saves storage. To use the module, the following command should be executed prior or together with sending any request for resources to the cluster manager.
# Use the module files module use /opt/insy/modulefiles # Check the available applications module avail
Example of output
—————————- /opt/insy/modulefiles —————————–
albacore/2.2.7-Python-3.4 cudnn/9.2-7.2.1.38
cuda/7.0 cudnn/9.2-7.3.1.20
cuda/7.5 cudnn/9.2-7.4.1.5
cuda/8.0 cudnn/9.2-7.4.2.24
cuda/9.0 (L) cudnn/10.0-7.3.0.29
cuda/9.1 cudnn/10.0-7.3.1.20
cuda/9.2 cudnn/10.0-7.4.1.5
cuda/10.0 (D) cudnn/10.0-7.4.2.24 (D)
cuda/10.1 devtoolset/6
cudnn/7.0-3.0.8 devtoolset/7
cudnn/7.0-4.0.7 devtoolset/8 (D)
Note that L is the loaded application, D is the default choice if requested without mentioning the version. To load an application, use the following command.
# Activate applications: CUDA ver 9.0, CuDNN 9.0/7.4.2.24, Matlab R2018b module load cuda/9.0 cudnn/9.0-7.4.2.24 matlab/R2018b
Now it is time to send a request for resources to the central manager. There are two methods of requesting resources, i.e., interactive and batch. In interactive mode, we ask for instant resources with the highest priority. In most cases, the resources are directly allocated without scheduling or queuing. The best practices are that we can use it to quickly test our program with a small chunk of data before processing the entire dataset in batch mode or if we need extra resources, for example, to build a package from the source. Meanwhile, in batch mode, we send the request to the central manager that will put the request into the queue and allocate the resources accordingly when the time comes.
Interactive mode
The following command is to request an instant interactive session from HPC cluster.
# Interactive mode to get the shell of 2 CPUs, 16 GB RAMs, 1 GPU with Pascal architecture sinteractive --ntasks=1 --cpus-per-task=2 --mem=16g --gres=gpu:pascal:1 bash -il
Batch mode
In batch mode, we send an execution script via sbatch command.
sbatch [execution_script]
The execution script contains the configuration of resources we need. For example, the following script requests running a Matlab script using general partition, short QoS, 1 hour run time, 1 task, 2 CPUs, 4 GB of memory, no usage statistics, and use the current directory.
#!/bin/sh #SBATCH --partition= general #SBATCH --qos= short #SBATCH --time= 1:00:00 #SBATCH --ntasks= 1 #SBATCH --cpus-per-task= 2 #SBATCH --mem= 4096 #SBATCH --mail-type= END srun matlab < matlab_script.m
SLURM will put the request in the queue and allocate requested resources in turn. You can change the matlab with any program from any language programming you want such as python, R, Scala, Perl, etc. However, you have to make sure the program can be run in login nodes before sending it to SLURM (e.g., check with python -V for python). Also, the dependencies required by the program to run properly need to be installed beforehand. If not, you need to install it. Since non-sudo privilege is usually given, you need to install the application using the pre-built format (i.e., binary format) or build it from the source with prefix to an accessible location.
Also, note that only certain directories are shared within the cluster. You can not process, for example, files in /tmp of login nodes once the job runs in the worker nodes because the folder is local to login nodes and unknown to other machines. Check with df -h to get to know which directories are shared among machines in the cluster. The simplest rule is that your home directory must be shared among those machines so use home directory to store the data and the script.
The stages of the program works are as follows. 1) the input data, if any, will be transferred from the storage pool (NFS) to the local disk (usually /tmp of allocated machine); 2) The data then will be transferred to RAMs (via very high-speed bus, usually InfiniBand); 3) Computation occurs on the data in RAMs; 4) The output data transferred from RAMs to local disk; 5) Finally the data and the console logs, if any, transferred to the storage pool; 6) Task completed.
Some useful commands are frequently used:
# Check the status of the request squeue | grep [execution_script] # Cancel the request scancel [process_id]
Summary
High performance computing (HPC) is a great resource to do extensive computation on data. Most research agencies and universities have at least a cluster of HPC. A number of heavy-computation jobs such as logistics optimization and number factorization are perfectly fit with HPC. In its architecture, HPC clusters the processing & memory in a separate group which is extremely-fast connected with the storage cluster. SLURM is responsible to allocate resources requested by a job that is submitted by a client. Nowadays, the architecture is challenged by the embarrassingly massive distributed platform such as Hadoop & Spark that uses commodity hardware and could be scaled out horizontally.