In the previous post, the flexibility given by data science tools greatly reduces the performance, i.e., the execution speed.
Fortunately, Dataiku, a data science tool, provides multiple ways to aggregate big data:
1) using the built-in building blocks;
2) using a custom R script with the built-in I/O blocks; or
3) using an independent custom R script (data processing using data.table package).
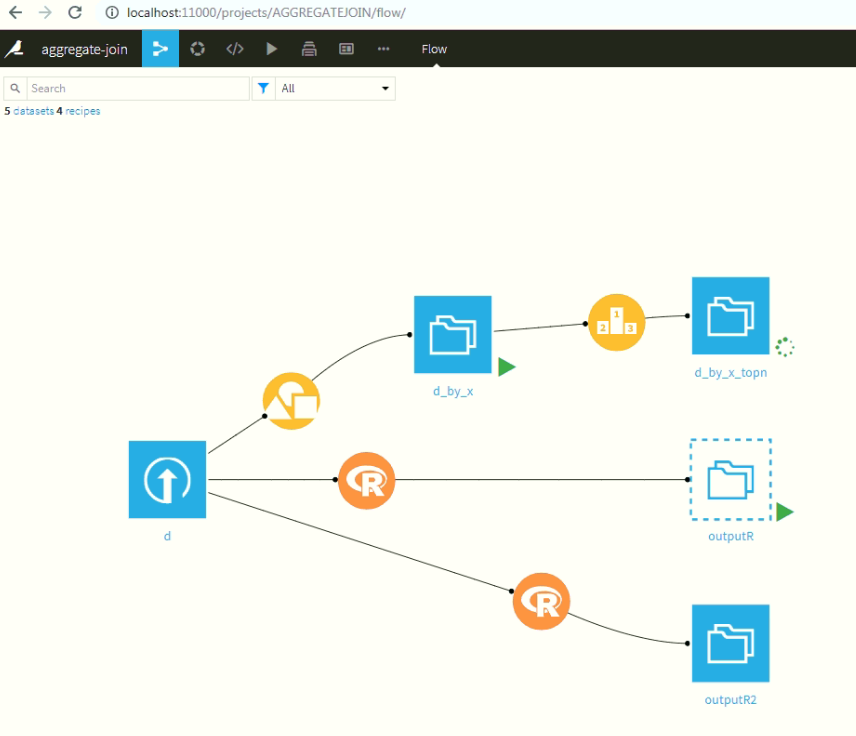
The R script embedded in the block is as follow. The data could be downloaded from here.
library(data.table)
d = fread("/scratch/awahyudi/d.csv")
setnames(d, c("x", "y"))
print(head(d[, list(ym=mean(y)), by=x][order(-ym)],5))
Here is the result of aggregating 100 million rows dataset on 16 CPUs, 114 GB RAM machine:
1) ~ 27 minutes
2) ~ 18 minutes
3) 9 seconds
Combining the inclusion of custom codes and the richness of UI & features in a platform such as Dataiku gets both benefits (flexibility & performance).