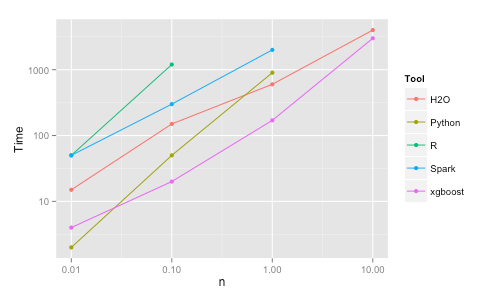
Will steep improvement of algorithm + decrease on hardware cost (CPU, memory, disk) drag the distributed approach irrelevant?
IMHO, at this time, the winner is h2oai which gives an impressive performance in stand-alone mode and supports distributed platform (i.e., atop Spark using h2o sparkling water). I was so surprised that Standford’s statistics maestro, Tibshirani & Hasti, are the advisor. Their book is the best statistics book I ever read.
Nice picture to calibrate which skill we should leave and engage as a data scientist.