NVIDIA Jetson TX2, a 64-bit arm board equipped with 256 CUDA cores (Pascal architecture), has arrived at the home during the holiday season. I was so lucky having the board together with the development kit for only 300 Eur, including the shipping fee (from UK to NL) due to the educational discount (the normal price is 622 Eur). The board size is very small, comparable with a credit card. However, to use it, a developer board (mini-ITX) or a carrier board is needed.
Size of Jetson TX2 Board (Source: https://eenews.cdnartwhere.eu/sites/default/files/styles/inner_article/public/sites/default/files/images/2017-03-10-s20_nvidia_jetson_tx2_embedded_ai_supercomputer.jpg)
The question is why this module is matter in the first place? Well, on many occasions such as a mission-critical task, it is not advantageous for sending the image/video from the local camera to a remote system for processing due to unacceptable response time, lack of network bandwidth, unreal-time decision making, etc. Therefore, it’s so much better to put the “inference” brain locally, the strategy what today’s people coin as “AI edge computing”. The use of GPU for inference has risen over the years and beaten its CPU counterparts (even from the desktop ranges). Last year, NVIDIA launched TX2 that could infer 250 images per second using GoogleNet trained model by drawing only10 Watt! This performance is similar to Intel E5-2960 v4 (14 cores, 28 threads), a server-class CPU that consumes 135 Watt.
TX-2 inference performance of Jetson TX2 is similar to Xeon E5-2960 v4 but much less power consumption (Source: https://devblogs.nvidia.com/parallelforall/wp-content/uploads/2017/03/Jetson_TX2_perf_Figure_3-1-e1488927262829-624×333.png)
Here are some reviews: 1) The first thing to do is to power up the board using the developer kit. NVIDIA makes the process very easy by providing users the JetPack package that includes all necessary applications and libraries to perform deep leaning inference, such as CUDA, cuDNN, TensorRT, VisionWorks, and OpenCV. The step is more less flashing the eMMC of TX2 from the PC. Once booting up, it’s loaded with Ubuntu 16.04. There are 5 modes of operation which offers between max-P (power saving)andmax-Q (quality). In max-Q mode, i.e., mode 0, all 6 cores are online and the frequency sets to be maximum (~ 2000 MHz). Meanwhile, in max-P mode, i.e., mode 4, only 2 cores are online and the frequency reaches as low as 300 MHz. I tried the GPU performance on mode 0 by running CUDA examples, such as oceanFFT, marchingCubes, etc. There is an increase in power consumption, i.e., from 4 Watt (idle, min frequency) to nearly 10 Watt (peak, max frequency). Unfortunately, like other boards having an onboard ethernet, wakeonlan is not supported.
Running 3D simulation using Jetson TX2
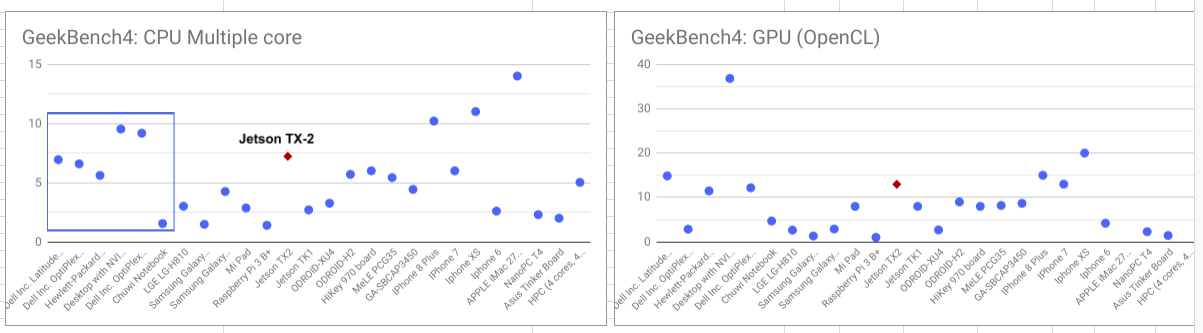
2) Next thing to do is to perform a benchmark with other similar processors (using Geekbench4 and Phoronix). Compared to other low-powered single-board computers (SBC) such as Raspberry Pi 3 B+, Banana Pi, and Odroid, Jetson TX2 (Max-Q) leads away. The closest competitors from ARM class are SBCs from Huawei Kirin 970 (HiKey 970) and Apple A10 (iPhone 7), meanwhile, SBCs from x86-64 class are Intel Apollo Lake J-series such as MeLE PGC 35 and Asus Tinkerboard. Its GPU performance is remarkable, comparable with high-end desktop Intel HD GPUs such as 4600 or 5500 or Apple A10 GPU. Despite the remarkable performance, I wonder why NVIDIA preferred Aarch64 architecture to x86-64. Operating ARM processors is challenging due to many existing applications are not supported. I found difficulties to find ARM docker images, such as Anaconda and Jupyter, and install applications like Geekbench4. Everything should be built from the ground or relying on NVIDIA support. The only fast workaround is using emulator software such as Exagear. However, the price seems so expensive for emulating x68 only than x86-64. IMHO, NVIDIA keeps using Aarch64 following their success with Tegra K1.
CPU and GPU Benchmark between Jetson TX2 and other ARM/x86-64 CPUs
3) Next, I tested the board with its ultimate goal, i.e., doing a vision related job. For such a reason, we started with OpenCV, the most popular Computer Vision application. Actually, from Jetpack 3.3, python has been compiled with OpenCV 3.3. However, I built OpenCV 3.4.1 instead of 3.3, following the guidelines provided by @jetsonhacks ( https://github.com/jetsonhacks/buildOpenCVTX2). I then run an edge detection program from 2 live cameras simultaneously. The algorithm worked in real-time fashioned, looked very smooth doing its job.
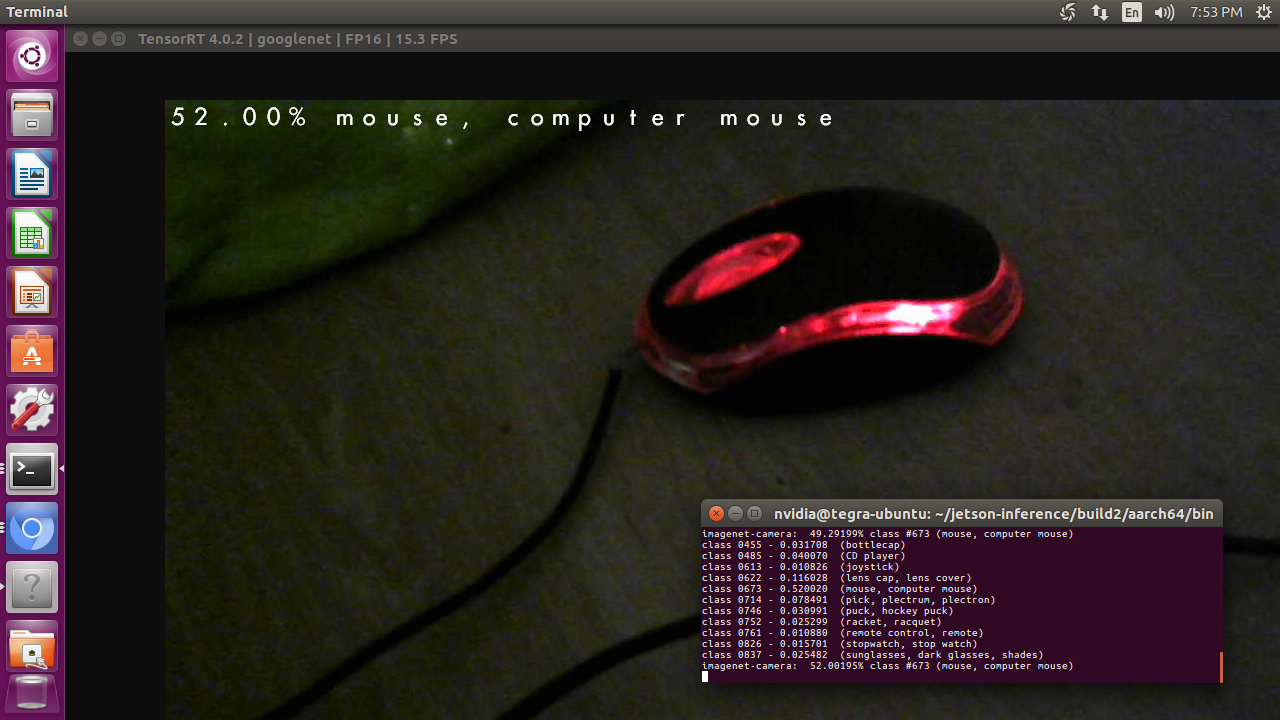
3) I then tested the board with AI inference task by using Alexnet and Googlenet trained model, following the guides from @dustynv ( https://github.com/dusty-nv/jetson-inference). There are 3 inference types in his GitHub, i.e., 1) image recognition classification, 2) object detection localization, and 3) segmentation free space. I tried a live image recognition task using Googlenet model and got ~ 15 frames per second. I have not tried to retrain the model nor have a batch inference because I do not want to spend much time in this stage.
image recognition classification using googlenet model
Things to do in the future: 1. Building everything in a docker container (openCV, python, TensorRT, VisionWorks). It will speed up the deployment stage. 2. Collecting all trained model (in a repository?) such as Mobilenet, Yolo, VGG, etc. 3. Retrain a deep learning model, and reinstall the model back to Jetson TX-2. 4. Having a real-world scenario (e.g., real-time object classification on my bike, real-time count on people in a room in SmartHome project?). A lighter carrier such as J120 might be needed.